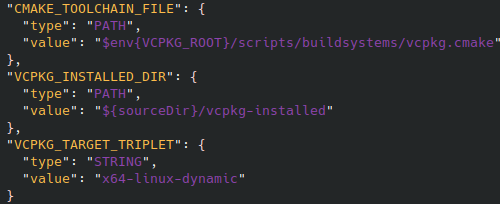
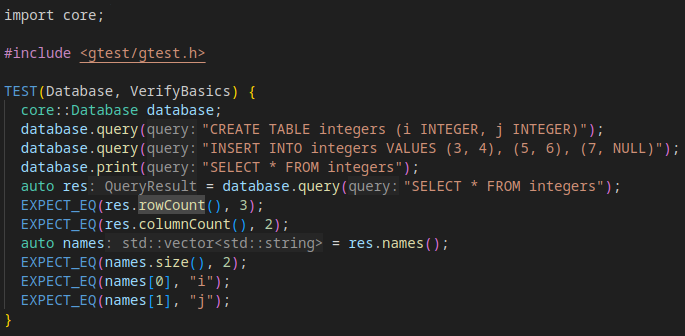
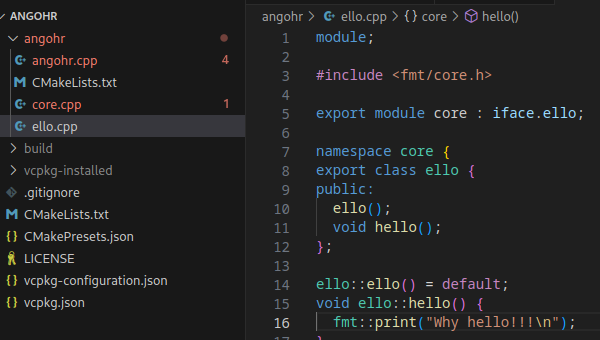
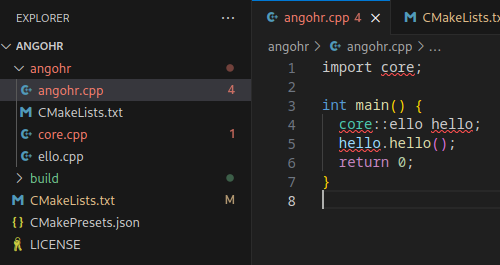
Fernanda recently posted about her GTC journey and it got me thinking about mine. Our careers have been somewhat adjacent for many years but it wasn’t until I joined Voltron Data that we actually worked at the same company. I was taking a look trying to remember, and I see photos from GTC 2014 that I think was my first, then speaking at GTC 2015 and there was a tutorial I gave the following year.
| Home | Archive | Categories |